Multi-Cloud Orchestration with Python
TLDR: I used the strategy pattern to orchestrate operations on worker instances in multiple clouds while exposing only one interface to clients. Code can be found here.
Hello world!
Automating workflows and processes in the cloud is a common task for system administrators, data scientists and all kind of engineers. Therefore, I would like to showcase a coding problem I had while automating the orchestration of cloud instances. The problem could be solved by refactoring the code and applying a design pattern.
The question I had at the beginning was:
How to orchestrate multiple worker instances in multiple clouds with python?
An Instance could be a Digitalocean Droplet an AWS EC2 Instance or an Azure virtual machine. On the first glance this seemed easy to solve. The first proof of concept created one function per cloud provider as in the code snippet below:
def create_worker_aws():
# talk to the aws api
def create_worker_digitalocean():
# talk to the digitalocean api
This was not an ideal solution but did work. The disadvantage here is, if you want to implement another cloud provider you have to change things in multiple parts of the code base. The command line layer may have a function like the following:
def create_worker(worker_name,cloud_name):
if cloud_name == "aws":
worker = create_worker_aws(worker_name)
elif cloud_name == "do":
worker = create_worker_digitalocean(worker_name)
For every new cloud provider I would have to write another elif statement and this for all operations of the worker nodes. So, the underlying problem is that we would like to have a choice of the implementations for similar behaviour. There has to be a better way to implement this.
The Strategy Pattern
To solve this, we can refactor the code to implement the strategy pattern. The Intent of the strategy pattern is:
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
In this scenario the “family of algorithms” are the different create,delete and list methods per cloud provider. Each algorithm is encapsulated by the previously defined context, in this scenario which cloud provider we would like to interact with.
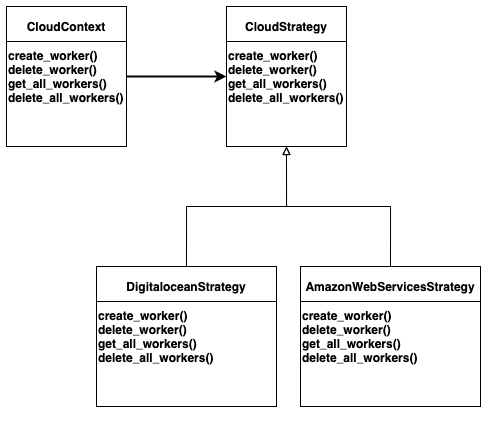
The CloudContext object contains a reference to the strategy we would like to use and is used in other places as an interface to the cloud provider. The abstract class CloudStrategy defines all the Methods every subclass of Strategy has to implement. Implementing the API calls to the cloud provider is done in the DigitalOceanStrategy and AmazonWebServicesStrategy classes. So at runtime we create a CloudContext object which contains the reference to the DigitalOceanStrategy or AmazonWebServicesStrategy. For the caller of any CloudContext method like create_worker or delete_worker it does not matter which Strategy we use.
Implementation
I created an example GitHub Repository for this solution. To use this code you have to build the dockerfile and write the credentials of the Cloud provider in the YAML configuration files as mentioned in the README. Below I will try to explain the most important parts of the code. Keep in mind that the repository is only for the example of implementing the strategy pattern.
CloudContext.py
from abc import ABC, abstractmethod
class CloudContext():
def __init__(self, CloudStrategy):
self._CloudStrategy = CloudStrategy
@property
def CloudStrategy(self):
return self._CloudStrategy
@CloudStrategy.setter
def CloudStrategy(self, CloudStrategy):
self._CloudStrategy = CloudStrategy
def create_worker(self, worker_name=None):
return self._CloudStrategy.create_worker(worker_name)
def delete_worker(self, worker_name):
return self._CloudStrategy.delete_worker(worker_name)
def delete_all_workers(self):
return self._CloudStrategy.delete_all_workers()
def get_all_workers(self):
return self._CloudStrategy.get_all_workers()
The CloudContext class specifies the Interface with which we will work to orchestrate the Cloud instances. At the initialization of the CloudContext we specify a strategy to use. Thanks to the CloudStrategy.setter we can change the Strategy after the first initialization of the object. The important part here is that every call to CloudContext.create_worker is directly passed to Strategy.create_worker.
CloudStrategy.py
from abc import ABC, abstractmethod
class CloudStrategy(ABC):
@abstractmethod
def create_worker(self, worker_name=None):
pass
@abstractmethod
def delete_worker(self, worker_name):
pass
@abstractmethod
def delete_all_workers(self):
pass
@abstractmethod
def get_all_workers(self):
pass
In the abstract CloudStrategy class are all common operations declared which have to be implemented by the strategies. The CloudContext uses this interface to call the methods e.g. create_worker defined by our concrete Strategies DigitalOceanStrategy and AmazonWebServicesStrategy.
For the concrete strategies I’m not going to explain all the API calls, this is thoroughly done in the API documentation.
DigitalOceanStrategy.py
from cloudcontroller.CloudStrategy import CloudStrategy
from utils.utility import init_logging
from digitalocean import SSHKey
from model.WorkerModel import Worker
import traceback
import digitalocean
import time
class DigitalOceanStrategy(CloudStrategy):
def __init__(self,config):
try:
self.logger = init_logging(__name__)
self.token = config['do_key']
self.region = config['region']
self.droplet_size = config['worker_size']
self.snapshot_id = config['image_id']
self.manager = digitalocean.Manager(token=self.token)
self.droplets = []
except Exception as e:
self.logger.error(
f"__init__@DigitalOceanStrategy.Exception: {e}\nTraceback\n{traceback.format_exc()}\n")
def create_worker(self,worker_name=None):
try:
droplet_name = worker_name
droplet = digitalocean.Droplet(token=self.token,
name=droplet_name,
region=self.region,
image=self.snapshot_id,
size=self.droplet_size,
ssh_keys=self.manager.get_all_sshkeys(),
backups=False)
droplet.create()
cond = True
while cond:
actions = droplet.get_actions()
for action in actions:
action.load()
if action.status == "completed":
cond=False
# This sleep does prevent rate limiting when creating instances in a loop
time.sleep(8)
return True
except Exception as e:
self.logger.error(
f"create_worker@DigitalOceanStrategy.Exception: {e}\nTraceback\n{traceback.format_exc()}\n")
return False
...
def get_all_workers(self):
try:
my_droplets = self.manager.get_all_droplets()
worker_list = []
for droplet in my_droplets:
worker = Worker(droplet.name, droplet.size_slug, droplet.ip_address, droplet.created_at)
worker_list.append(worker)
return worker_list
except Exception as e:
self.logger.error(
f"get_all_workers@DigitalOceanStrategy.Exception: {e}\nTraceback\n{traceback.format_exc()}\n")
return False
The DigitalOceanStrategy makes the API calls to the actual API. In the __init__ method we are configuring the object with the previously read values from the YAML file. The create_worker method calls digitalocean.Droplet to create the Droplet and waits afterwards for the droplet to change his state to completed.
class Worker():
def __init__(self,worker_name, worker_size, worker_ip, created_at):
self.name = worker_name
self.size = worker_size
self.ip = worker_ip
self.created_at = created_at
One remaining problem we have is the different ways of the cloud libraries in representing their instances. In the digitalocean library we have Droplet objects and in AWS there are Instance Objects. To simplify this I created a Worker class and the get_all_workers method does return a list of type Worker.
main.py
import yaml
import random
import string
from model.WorkerModel import Worker
from cloudcontroller.CloudContext import CloudContext
from cloudcontroller.AmazonWebServicesStrategy import AmazonWebServicesStrategy
from cloudcontroller.DigitaloceanStrategy import DigitalOceanStrategy
def read_config(file_path):
config_file = open(file_path)
config_dict = yaml.load(config_file, Loader=yaml.FullLoader)
return config_dict
def main():
aws_config = read_config("config/aws.yaml")
do_config = read_config("config/digitalocean.yaml")
digitalocean_strategy = DigitalOceanStrategy(do_config)
print("Cloud context set to Digitalocean")
cloud_context = CloudContext(digitalocean_strategy)
worker_name = ''.join(random.choices(string.ascii_uppercase + string.digits, k=10))
print(f"Create worker {worker_name} - {cloud_context.create_worker(worker_name)}")
worker_list = cloud_context.get_all_workers()
print(f"Worker Objects: {worker_list}")
for worker in worker_list:
print(f"Worker: {worker.name} | {worker.ip} | {worker.size} | {worker.created_at}")
print(f"Delete all workers - {cloud_context.delete_all_workers()}")
print("Switching context to AWS")
aws_strategy = AmazonWebServicesStrategy(aws_config)
cloud_context.CloudStrategy = aws_strategy
worker_name = ''.join(random.choices(string.ascii_uppercase + string.digits, k=10))
print(f"Create worker {worker_name} - {cloud_context.create_worker(worker_name)}")
worker_list = cloud_context.get_all_workers()
print(f"Worker Objects: {worker_list}")
for worker in worker_list:
print(f"Worker: {worker.name} | {worker.ip} | {worker.size} | {worker.created_at}")
print(f"Delete all workers - {cloud_context.delete_all_workers()}")
if __name__ == "__main__":
main()
Now let’s use our CloudContext to implement the same behaviour for multiple cloud providers. First we are reading the YAML configuration files aws.yaml and digitalocean.yaml. Then we are using the DigitaloceanStrategy to create a worker, list all workers and delete all workers. After this we’re switching to the AmazonWebServicesStrategy with the statement cloud_context.CloudStrategy = aws_strategy. Then the same steps as for the DigitaloceanStrategy are repeated. The command line output is the following:
root@89c345957da5:/code# python main.py
Cloud context set to Digitalocean
Create worker GQILWLK94F - True
Worker Objects: [<model.WorkerModel.Worker object at 0x7ff8fd5debb0>]
Worker: GQILWLK94F | 167.172.170.184 | s-1vcpu-1gb | 2021-01-24T10:29:30Z
Delete all workers - True
Switching context to AWS
Create worker EVWNOQO82C - True
Worker Objects: [<model.WorkerModel.Worker object at 0x7ff8fccb6520>]
Worker: EVWNOQO82C | 18.194.44.5 | t2.micro | 2021-01-24 10:30:40+00:00
Delete all workers - True
So with this working, we can now use the CloudContext to orchestrate multiple instances in multiple clouds without a lot of if statements or inheritance.